CLevel Hash for PM
Persistent Memory (PM)
- DRAM是易失的,掉电后数据都会丢失,需要较多地考虑存储的一致性和持久性问题;而PM是非易失的,但在读写延迟与带宽上存在以下不足。
- Compared with DRAM, PM has 3x read latency and similar write latency
- The read and write bandwidths of PM achieve 1/3 and 1/6 of those of DRAM
- 针对传统DRAM的WAL和COW技术都存在大量的写入,没有考虑PM非易失、写入表现差等特点。
Level Hash
有关Level Hash的具体内容参见左师兄在OSDI2018上发的文章:”Write-Optimized and High-Performance Hashing Index Scheme for Persistent Memory”,我只阅读过一篇介绍文章,下面讲讲我对Level Hash的一些简单理解。
传统的hash table在插入数据时是线性复杂度,但当产生的哈希冲突无法解决,需要进行rehash时,时间开销将是巨大的,需要将hash table中的每一个元素重新进行hash.
针对传统的hash table,已经有了很多的改进方案,但很多都是基于DRAM的。左师兄根据PM的特点,提出了Level Hash.
“Level”的含义就是将hash table分层,论文中将其分为两层,top level (TL)是bottom level (BL)的两倍大小,以下是分层结构的逻辑视图。
关于Level Hash的介绍我也尝试写过,但还是觉得交大IPADS团队写的介绍简洁清晰且易懂,他们将OSDI2018中的每篇论文都做了简要介绍,将论文中的精华都提取出来。以下为从中摘取的insert操作和resize操作部分的介绍。
在进行插入x时,先查看两个哈希函数(hash1(x)和hash2(x))对应的上层桶是否有空闲的槽位,如果有则将键值对直接放入槽位,插入完成;如果两个上层槽位都满了,则检查在这两个都满了的桶中,看是否有键值对可以放置到其另外一个哈希函数的上层桶中(如键k在hash1(x)或者hash2(x)桶中,则看其能否被移动到hash1(k)或者hash2(k)的桶中),如果有,则将其移动过去,那么当前需要插入的键值对就有空间可以存放了;如果没有,则进一步检查hash1(k)和hash2(k)所对应的下层桶是否有空位(即检查hash1(x)/2和hash2(x)/2桶),如果有,则可直接插入;否则,进一步检查两个下层桶中的键值对,是否能被移动到其对应的其他下层桶中,如果可以,则将其移动过去,以给新插入的键值对腾出地方;如果依然没有,则整个插入过程失败。如果插入失败,则需要将整个哈希表变大一倍之后进行插入。从上述的步骤可以看出,一个成功的插入,最多只会迁移一个已经存在的键值对。因而这个方法可以保证哈希表插入的效率。
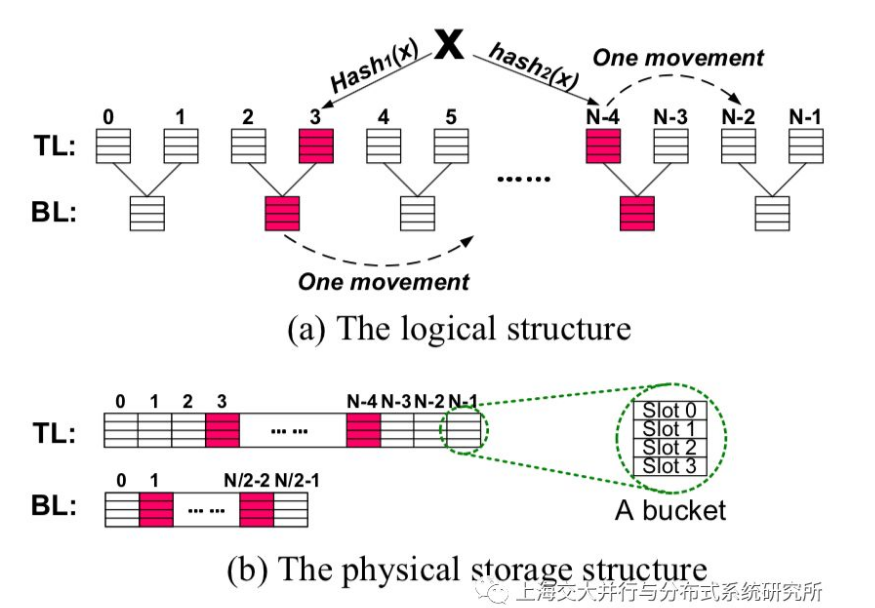
在进行增大操作时,加入原哈希表的上层桶数为N,则分配一个新的2N个桶的数组,将其作为新的上层,原来的上层则作为新的下层,而原来的下层则成为过渡层(图中IL)。此后,需要将过渡层中的所有键值对重新哈希(rehash)到新的上层中。当所有的键值对都被重新哈希到上层之后,可以将过渡层的空间释放掉。哈希表恢复为两层,这个哈希表调整过程结束。在这个调整过程中,被重新哈希的键值约为整个哈希表中键值对总数的1/3,因而这种方法优于传统的调整方法。
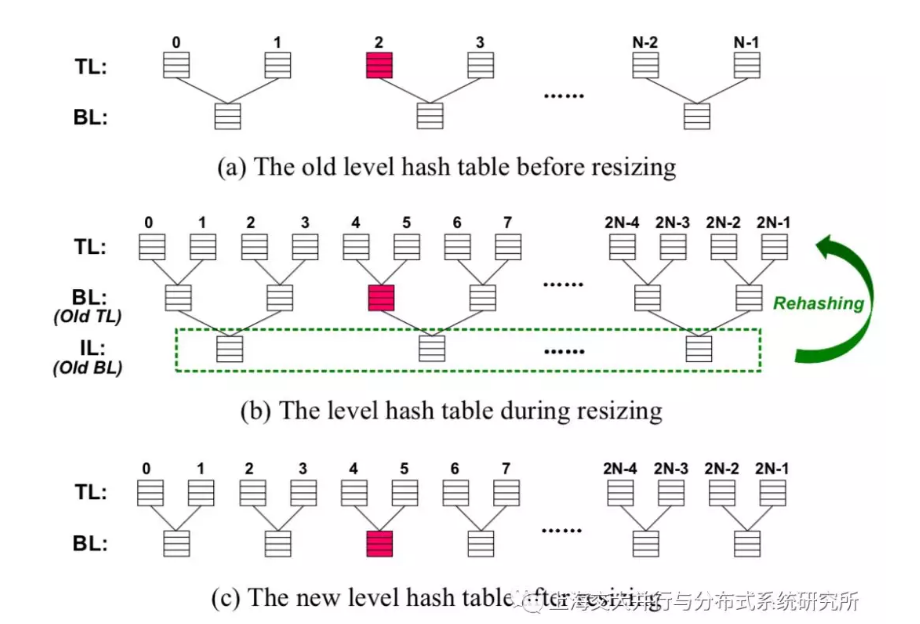
Level Hash减少了hash table进行resize时需要进行rehash的键值对总数,同时由于采用上下分层策略、使用两个hash函数,insert进来的项可以进入上下两层中的4个bucket. 由于每个bucket中有4个slot,每个insert项共有16个可选空位,而且如果bucket满了,还可以把bucket中的项放入该项的其他可选空位以腾出空间。这样一来,产生无法解决的hash冲突的概率大大降低,load factor指数大幅增加。而得益于结构设计的巧妙,得到这些收益的额外时间成本是较低的。
但是Level Hash仍然存在问题,或者说有待优化的地方。比如,Level Hash存在数据重复和数据丢失的问题、resize时会对hash table加锁,并block所有的query请求,这影响了系统的性能。

CLevel Hash
CLevel Hash 是Level Hash的改进版本,主要解决了数据重复和数据丢失问题,resize时不用对hash table加锁,且支持多层hash和并发rehash,论文见USENIX ATC 2020 “Lock-free Concurrent Level Hashing for Persistent Memory“。
CAS与COW
为了保证写入的正确性,有CAS和COW策略。
CAS即”Compare and Swap”,CAS有3个操作数:内存值V、旧的预期值A和要修改的新值B。只有当预期值A和内存值V相同时才将内存值V修改为B,否则什么都不做。但CAS也有缺点,他最多只能支持CPU一次写入的最大位数(如64bit,即8B)。
COW即Copy On Write””,当需要对某一数据块进行修改时,复制要修改的数据,然后在副本上进行修改,修改完成后将指向源数据的指针用CAS原语修改为指向修改后的副本数据的指针。缺点:未修改数据的额外写入。想象一下修改很大一个数据块中的一个字节会发生什么。
Level Hash存在的问题与优化
主要是数据正确性方面的问题。首先是数据重复,从上面的对比表中可以看出,Level Hash是对slot进行加锁。在每一个bucket的最前面有4*1bit的Tokens,用来标记对应的slot是否被写入。想象一个场景,假设有键值对(a,b)正在被插入,此时对应的slot被锁住,但是由于插入未完成,对应的Token仍然是0. 假设此时有另外一个线程也插入(a,b),那么他会在Token=1的slot中寻找重复,从而顺利插入进hash table. 这就是数据的重复。
然后是数据丢失,仍然是刚才的例子,假设(a,b)正在被插入进BL中的某一个slot,此时另外一个线程正在进行rehash,当rehash进行到(a,b)所在slot时,由于并未完成插入,所以对应Token为0. rehash线程将认为该slot无数据而跳过该slot,rehash完成后,BL将被释放,造成插入数据的丢失。
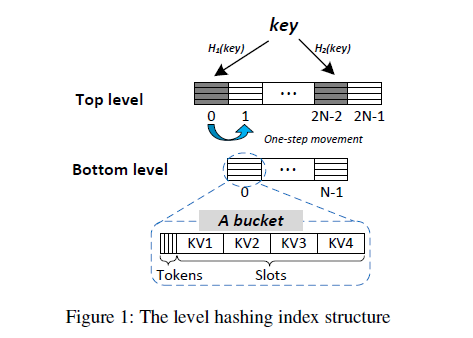
Dynamic Multi-level Structure and Concurrent Resizing
先来讲讲多级hash结构,在CLevel Hash中有多个level且level数量在动态变化,这些level构成了一个单向链表。两个level之间的bucket数量依然是2倍的关系,但一个bucket中有8个slot且slot中存放的是指向数据的指针,这使得存放的数据长度可以动态变化且保证数据更改的原子性(指针占用空间小于8B,所以其更新是原子的)。在CLevel Hash中,取消了Level Hash中的one-step movement(即bucket满时将其中的某一键值对移至备选slot的操作),减少了PM写入量,降低了load factor. 但由于每个bucket含有8个slot,CLEVEL-8-slot和LEVEL-4-slot的load factor表现差不多。
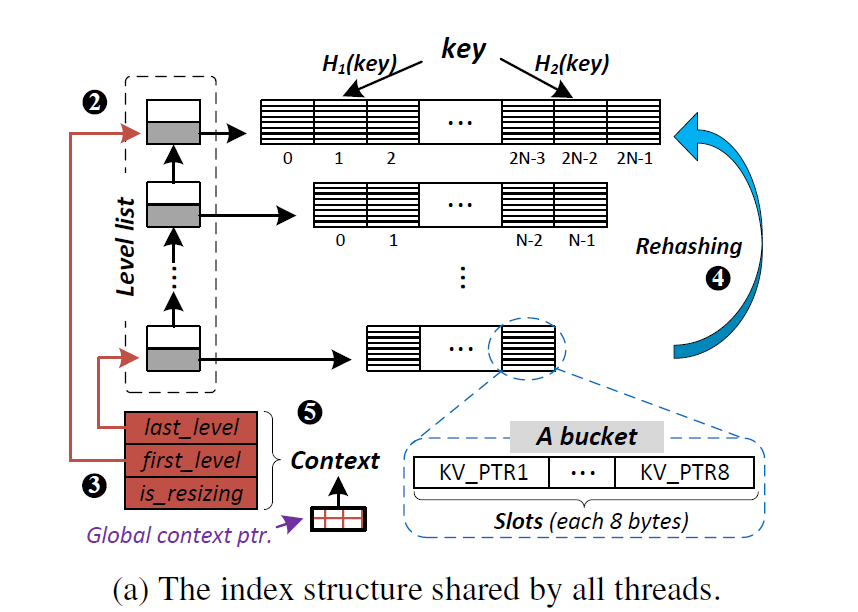
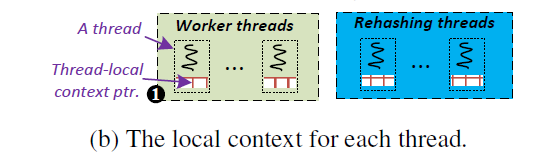
接下来是Concurrent Resizing. 先介绍一下这里的Context结构。Context结构包含两个指针和一个标志,两个指针分别指向最上层和最下层,is_resizing表示hash table是否在进行resize操作,Context结构大小为8+8+1=17bit. 程序中有一个全局指针global ptr,指向global context,同时,每个线程中也有一个local ptr,指向现在或过去某个版本的Context.
在CLevel中,rehash被分为expand和resize两部分,一共有5步。expand包含1-3步,resize包含4-5步。以下为简要说明,CAS的出错处理和步骤详细说明请见下面对应的代码分析。
- 复制global ptr到local ptr
- 使用CAS,将一个容量为first level的两倍的新level加入level单向链表中
- 使用COW+CAS,将Context中的first level更新,is_resizing设为true
- 将last level中每一个bucket中的slot进行rehash,插入first level中
- 使用COW+CAS,将Context中的last level更新,当hash table只有两层时,将is_resizing设为false
下面将结合源代码中的expand和resize函数进行具体说明。CLevel Hash的源码在此GitHub仓库中,expand和resize函数在文件Clevel-Hashing\include\libpmemobj++\experimental\clevel_hash.hpp中定义,在代码的1300行-1600行之间,以下分析仅抽取部分关键代码行进行说明。
expand
以下的1-5点为上述步骤的详细说明。
- 为了访问最新的Context
- 在第5行,更新链表的CAS操作失败,由于该CAS操作仅更新FirstLevel的上一层Level,所以肯定是其他线程也进行了expand操作。所以,在if语句块中(即6-8行)撤销tmp_level的空间分配,同时在11-15行的COW策略中不对Context的FirstLevel进行修改。
- 在11-19行的if-else语句块为COW操作,20-23行为CAS操作,进行Context更新。如果成功,则在22行退出,如果失败,则转至24行,更新Context。如果情况如第28行所述,则放弃本次expand;如果情况如第32行所述,则继续循环,重复第3步。
在第36行的else语句块部分在论文中没有提及,主要目的是加速expand过程。
1 | if (cl->up == nullptr){ // FirstLevel->up为空,可以正常执行第2步 |
resize
在此部分中,resize也被称为rehash,可能与上面会有些冲突,请读者注意鉴别(论文中这一步叫rehash,但代码中又是resize函数,所以有点混淆)。
- 如果17或25行的CAS失败,就会继续寻找一个空的slot. 如果两个备选bucket中都找不到空位,则进入32行,对hash table进行expand操作,然后重试本次rehash,之前已经rehash过的slot保持原样。(即在expand后的hash table中,之前rehash过的slot在第二层,正在rehash的slot以及在这之后的slot都将rehash至第一层,也就是top level)。对last level的遍历是由第一行的while循环、第6行的定位待hash的bucket的操作和第37行的递增操作一起完成的。
- 第39行的if语句判断是否resize完毕,COW+CAS更新Context信息的错误处理见代码。值得注意的是,在54行,如果完成本次resize,level数不等于2,还将继续进行resize.
1 | while (run_expand_thread.get_ro().load()){ |
总结
insert操作在遇到无法解决的hash冲突时,执行完expand操作后就可以继续进行其他query操作了,resize操作将在后台进行,这改善了由rehash造成的长时间无法执行query操作的情况。再来看hash table的多级结构,expand退出后,resize还在进行,此时可能有insert造成的expand或者resize本身造成的expand出现,从而使hash table出现3层或更多的情况,resize将一直进行,直到hash table变为2层,此时将is_resizing设为false. resize操作也可以并发进行,论文在3.1.2的最后一部分谈到了这点,但是在代码中好像没有实现,我看resize中的错误处理中好像没有应对并发resize出错的措施。
Lock-free Concurrency Control
待更新……